

Agentialism and the Free Energy Principle
When do things become agents, and what is agency?


“If you don't control your mind, someone else will.” John Allston.
Caveat emptor: agency doesn't imply non-determinism, this article does not take any position on the free will question.
Language models have no agency, duh

Every time you use an LLM, you are sequestering your agency. Language models don’t have any agency, you do. Language models are not things in the world, but they can be seen as virtual things using our (forthcoming) definition of nonvirtual agents but they are much more sclerotic than memes. Language models only become embedded in cognitive processes when you use them.
Is GPT “understanding-promoting” or “understanding-procrastinating”?
ChatGPT allows you to do slightly more work, faster than you otherwise could without understanding, but as soon as you need to take the task seriously, then you need to make up the ground you lost by using GPT in the first place. Ultimately, there is no substitute for understanding. The debt must always be paid, if not by you, then by someone else.
One of the reasons highly technical people get so much out of GPT models is that they already understand technical topics deeply, and can quickly discard incoherent confabulations and drive into detail. The “denovo” story is a bit different. A beginner doesn’t know what they don’t know, and hence — wouldn’t know how to query ChatGPT. I use the word query intentionally, because it is akin to querying a database. I like the paintbrush analogy from Gary Marcus too, but the database analogy is better, for reasons I might write about in the future.
Do you ever find yourself in the situation where you have “written” a significant amount of code, it compiles, and you only vaguely know what it supposed to do — you have no earthly clue how it works because you’ve been tapping the generate button on GPT-4 like a mindless moron?
Just like it is with the phenomenon of change blindness / selective attention — when you are so focussed on GPT garbage, the part of your brain which understands, plans and acts is impaired. You try and switch between the modes of cognition dynamically, much like passing a metaphorical baton. It’s an inefficient process and is the worst form of context switching.
(Video source from YouTube). This famous gorilla experiment demonstrates the concept of selective attention in humans.
There is a good chance that GenAI will dumb-down software engineering in much the same way that “Doomscrolling” on TikTok is making our kids dumber. TikTok might be a bad example though, as you could argue it’s an entropy-maximizer rather than Github Copilot which is clearly an entropy-minimizer. TikTok is quite similar to Kenneth Stanley’s picbreeder!
Have you ever heard yourself say to your colleagues “this is blowing up in complexity guys!” — and they frown and assume you didn’t understand it? Part of understanding is constructing and linking together reference frames of knowledge to create a high-fidelity shared world model. Generally speaking, if your model is complex, you don’t understand. That’s why we don’t understand intelligence by the way, everyone has a different model for it.

When you are in the middle of the Mandelbrot set you’re okay. Everything is nice and predictable. You’re in a warm fuzzy place. This is where GPT lives. GPT is trained to be entropy-minimizing. In GPT-land you will only ever see boilerplate-city, a sea of mundane repetition. It’s the job of the prompter to get the model as close to the entropic boundary as possible.
When you “automate” a language model on a schedule, it’s no different to using any other piece of code running on a schedule. The magic disappears doesn’t it? That’s because when you use the language model, it’s embedded into your cognitive nexus of planning, understanding and creativity. As soon as it runs autonomously, it discombobulates, it dissolves, it decoheres. Look at this example of me repeatedly driving RunwayML on our MLST pineapple logo. See what happens? When this is an interactive process such as with ChatGPT, we push towards the entropic chaos on the boundaries, but it’s physically grounded every step of the way. That’s why we can coax more entropy out of GPT, by pushing it again and again towards the boundaries.
There is nothing but complexity on the boundaries. It represents the tyrannical sea of edge cases. We can traverse to the edges in an infinite number of directions. The curious thing is that we maintain coherence. Autonomous AIs decohere — and we don’t, because we have agency, and AI’s don’t. This is quite similar to the concept of the “wall of fire” in the Battlefield Royale Games which appears when the time is running out in a game. AI models don’t like high entropy/information — you have to push them as hard as you can to the boundaries to complexify their output with clever prompting (i.e. entropy smuggling), and if you are not there to do this interactively, they will “mode collapse” (the wall of fire) into a sea of nothingness.
Does a scriptwriter for a film have a goal? Does the director have a goal? What is the directors goal? What is the editors goal? Is what emerges in the end the same thing as what the scriptwriter imagined?
When I edit videos, I know that the direction of the video emerges from the material, which emerges from situation of whence the material was filmed because it’s a materialisation of a physical cognitive process. It’s impossible for me to even think about the film without the material present, because as Andy Clark argued in supersizing the mind — the material not only extends my mind but also forms the basis of my agency.

Recently, my microwave oven developed agency. It started making annoying noises in the middle of the night, and it always seemed to know when I was there, because like the observer effect in quantum mechanics - it would always pull its socks up and be quiet when I was physically in the room! I set up a camera to study this new creature, I wanted to discover what it wanted - what its goals were, and perhaps even, if it was sentient.
Maxwell Ramstead’s “Precis” on the Free Energy Principle.
The free energy principle is a mathematical principle that allows us to describe the time evolution of coupled random dynamical systems. The perspective opened up by the FEP starts from the question of what it means to be an observable thing in our physical universe
.. at least, according to Dr. Maxwell Ramstead who recently published “The free energy principle - a precis”.
I really recommend reading it actually, it’s only a five minute read — it’s enlightening.
I highlighted a few things from it last night, which I am recapitulating here to help set the frame for what’s coming next on agency.
He said that the FEP allows us to partition a system of interest into “particles” or “things” which can be distinguished from other things.
The free energy principle rests on sparse coupling, that is, the idea that “things” can be defined in terms of the absence of direct influence between subsets of a system.
Subsets of the system, are the things, if they exhibit certain properties.
Markov blankets formalize a specific kind of sparseness or separation between things in the system, which help us identify the things from the non-things.
Ramstead notes that this self-similar pattern repeats at every scale at which things can be observed—from rocks to rockstars, and beyond.
He said that, the free energy principle tells us something deep about what it means for things to be coupled to each other, but also distinct from one another. It implies that any thing which exists physically—in the sense that it can be reliably re-identified over time as “the same thing,” will necessarily look as if it “tracks” the things to which it is coupled.
The free energy principle is based on the idea that sparseness is key to thingness. The main idea is that thingness is defined in terms of what is not connected to what. Think of a box containing a yellow gas, as opposed to a box containing a rock. In a gas, we have strongly mixing dynamics: any molecule in the gas could find itself arbitrarily connected to any other, such that no persistent “thing” can be identified in the box. By contrast, a rock does not mix with or dissipate into its environment. In other words, the rock exists as a rock because it is disconnected from the rest of the system in a specific way.

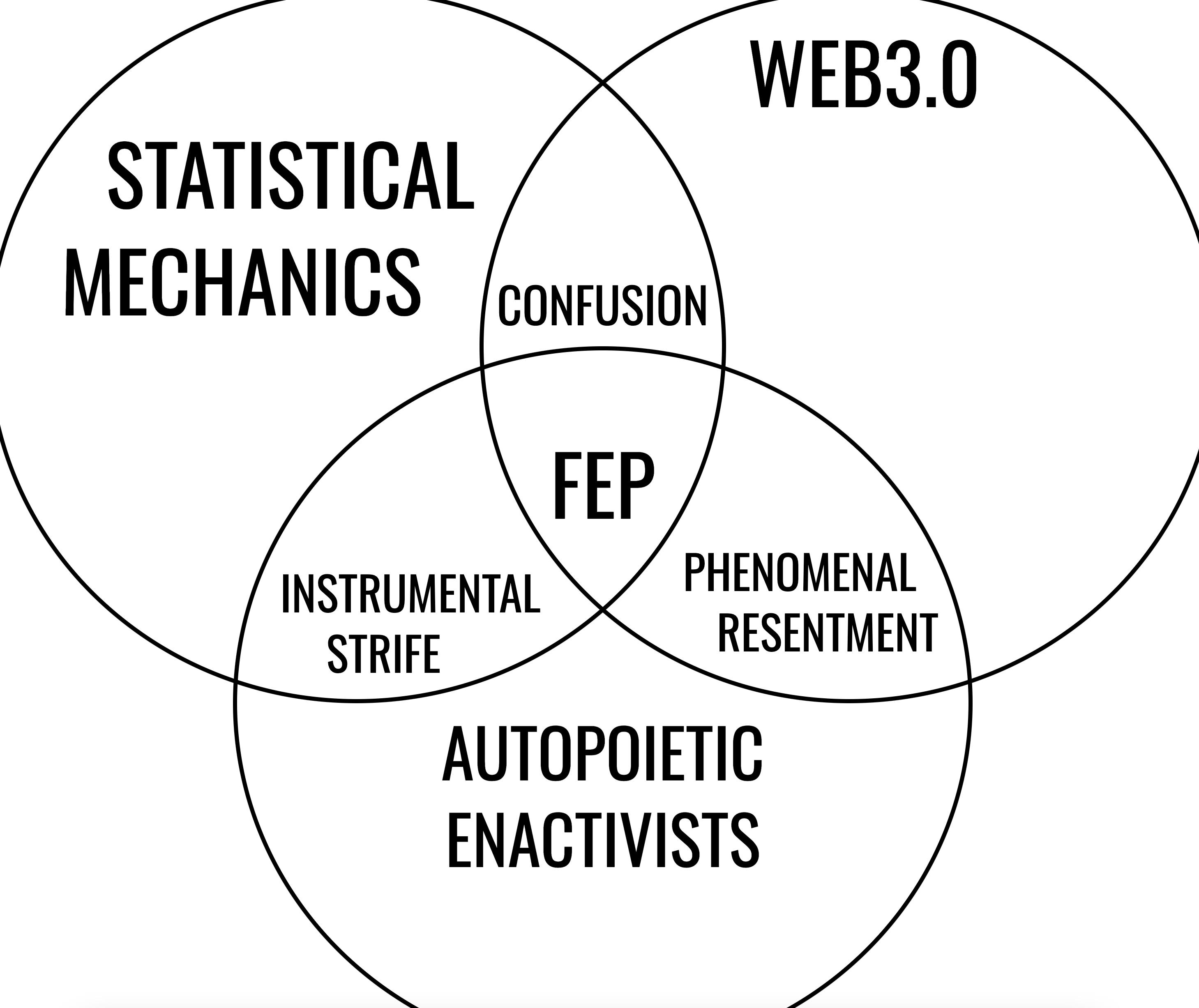
Maxwell concluded that the free energy principle stands in contrast to approaches which would split the sphere of mind or life from the sphere of physical phenomena, such as some versions of the autopoietic enactive approach. He said that the FEP eschews all such distinctions and embraces a physics of thingness that ranges from subatomic particles to galaxy clusters—and every kind of thing in between.
So, when he says the free energy principle "eschews all such distinctions" he means it proposes a monistic view where everything is encompassed within the same physicalist framework without a need for a separate ontological category for mental or life-like processes. The thing is though - as I understand it, autopoetic enactivists are still monoists.
Autopoietic enactivism typically embraces a form of biological monism, where cognition and life are deeply entwined, and the organisational properties of living systems are central. However, it does not necessarily prioritise physical explanations in the same way as the FEP does.
Varela and Maturana, suggested that living systems are self-producing (or autopoietic) and maintain their identities through continuous interactions that enact or "bring forth" their world. This kind of monism could be seen as having an idealist flavour because it emphasizes the primacy of the living organism's experiential world and the constitutive role of its actions in shaping its reality.
But basically, enactivist frameworks tend to ascribe a special status to biological processes that are distinct from mere physical processes. This could read as a form of dual-aspect monism, which accepts only one substance (hence monism) but insists on fundamentally different aspects or properties, such as the physical and the experiential (though still resisting the complete mind-body dualism of Descartes).
Finally, He also argued that this philosophical perspective is not physicalist reductionism (which is to say a reduction of causal efficacy to “mere” physics)—but rather, a deep commitment to anti-reductionism, emphasising the causal contributions of things at every scale to the overall dynamics of the nested system.
Maxwell's statement could seem paradoxical at first glance—asserting that the Free Energy Principle (FEP) is not a form of physicalist reductionism despite being materialistic and placing everything within the framework of physics. However, there's a nuanced distinction to be made here between different flavours of materialism, and the type of reductionism he’s referring to.
Physicalist reductionism is often associated with the idea that all complex phenomena can and should be understood entirely in terms of their simplest physical components. This view suggests that the behaviour of higher-level systems (like organisms or societies) can be fully explained by reducing them to the interactions of their most basic physical parts (like atoms and molecules)—essentially a "bottom-up" approach which can overlook emergent properties that are not apparent when looking solely at these components in isolation.
In contrast, when Maxwell discusses the FEP as being committed to "anti-reductionism" — he appears to be aligning with a materialist view that recognises and seeks to account for the complex structures and behaviours of systems at all levels—acknowledging that these cannot simply be reduced to or fully predicted by their constituent parts. This aligns with the idea of emergent properties whereby higher levels of organisation (such as life, consciousness, or social structures) have characteristics that, although they arise from physical processes, are not readily explained by the laws governing lower levels of organisation.
This is Dr. Sanjeev Namjoshi, commenting on the above.
A key question is the relationship between things and agents. When do agents become things?
Realist or instrumental agency
The FEP does not strictly demand that a system's physical content be intrinsically linked to agency. Systems can be described as-if they are performing inference —a notion echoed in concepts like 'organism-centered fictionalism or instrumentalism' where the agent is modelled as-if it were coupled bidirectionally with its environment while in fact being a fictionalist account.
An important theme in the Free Energy Principle is whether it could be seen as an ontological or realist theory of how things actually work, or scientifically useful fiction or lens to help us understand the world.
Representations figure prominently in several human affairs. Human beings routinely use representational artifacts like maps to navigate their environments. Maps represent the terrain to be traversed, for an agent capable of reading it and of leveraging the information that it contains to guide their behavior. It is quite uncontroversial to claim that human beings consciously and deliberately engage in intellectual tasks, such as theorizing about causes and effects—which entails the ability to mentally think about situations and states of affairs. Most of us can see in our mind’s eye situations past, possible, and fictive, via the imagination and mental imagery, which are traditionally cast in terms of representational abilities.
In the cognitive sciences, neurosciences, and the philosophy of mind, the concept of representation has been used to try and explain naturalistically how the fundamental property of ‘aboutness’ or ‘intentionality’ emerges in living systems [1]. Indeed, living creatures must interact with the world in which they are embedded, and must distinguish environmental features and other organisms that are relevant for their survival, from those that are not. Living creatures act as if they had beliefs about the world, about its structure and its denizens, which guide their decision-making processes, especially with respect to the generation of adaptive action. This property of aboutness is thus a foundational one for any system that must make probabilistic inferences to support their decision-making in an uncertain world, which are central to the special issue to which this paper contributes.
(From Ramstead - Is the Free-Energy Principle a Formal Theory of Semantics? From Variational Density Dynamics to Neural and Phenotypic Representations)
Ramstead proposed a deflationary account of mental representation, according to which neural representations are mathematical, rather than cognitive, and a fictionalist or instrumentalist account, according to which representations are scientifically useful fictions which serve explanatory (and other) aims.
An important distinction highlighted here is that while systems might not really be maximising or minimising their free energy, they can be understood to behave as if they were under the modelling framework provided by maximum entropy—a principle originally introduced to inject probability into statistical physics by physicist Edwin Jaynes in the late 1950s.
Consequently, the "agent-ness" and "thing-ness" under the FEP are not necessarily disjoint concepts but rather different vantage points of an overarching framework that seeks to explain the behaviour of systems and agents in a consistent manner.
The relationship between being an agent and being a mere thing in the system lies in the degree to which the behaviour of the system is passive or active, inferred or imposed, and modelled or mechanistic within the FEP's theoretical landscape.
We will be getting my favourite AGI “doommongerer” Connor Leahy back on MLST soon. I naively thought that deconstructing goals as instrumental fictions would be a good way to disarm the Bostrom-esque “we are all going to die” type arguments. He assured me that almost all X-risk people already agreed with this position, and it wouldn’t move the needle!

Agential density and nonphysical/virtual agents
A system's 'agential density' might be analogised to the extent to which it actively regulates its internal states and interacts with the environment to fulfil its generative model—essentially acting upon its predictions and updating them in light of new sensory information. Systems with more complex and numerous active states that aim to minimise free energy through direct interaction with the environment could be thought of as having higher 'agential density' compared to simpler systems whose behaviour might be more reactive or less directed towards minimising free energy. Perhaps agential density might also be thought of as a degree of nesting, which is to say, an agent which nests mostly only other dense agents, is more of an agent itself as the agential power radiates upwards, so to speak.
In the recent show with Riddhi Jain Pitliya we discussed the idea of virtual or nonphysical agents, and we cited examples of culture, memes, language or even evolution. Professor Friston was a little bit wary of this idea, preferring to stick with the physical interpretation.
We can think of virtual agents as having active states and acting on the world, but in a much more diffused and complex way.
A revised approach to 'agential density' for such entities would necessarily focus less on direct physical interaction with the environment and more on the influence these entities exert over behaviours and structures. Here, 'agential density' could be reinterpreted as the degree to which these nonphysical entities exhibit coherent, goal-directed behaviours and maintain their structure within a social or economic space.
Since culture and markets lack physical Markov blankets, their 'boundaries' can instead be seen in terms of the information and practices that define them. These boundaries are more fluid and permeable than physical ones, and 'active states' in these contexts may refer to decision-making processes, the dissemination of cultural artefacts, or market signals that influence economic behaviour.
In framing 'agency' in this way — an instrumentalist perspective emerges which would view markets and cultures as 'agents' insofar as they effectively coordinate individual actions and information processing towards collective outcomes. Going on the precis piece from Ramstead earlier, he made it clear that newer formulations of the free energy principle already support this type of configuration i.e. “dynamic dependences … not physical boundaries”.
The interesting part is that these virtual agents can influence and diffuse the behaviour and agency of the physical agents via top-down causation, much like socially-embedded categories influence our own behaviour.
Strange bedfellows
Prof. Mark Bishop spoke with us on an MLST interview in 2022. He is an autopoietic enactivist. The main difference between his position and the FEP folks is the focus on biology, autopoiesis (biological autonomy through self-producing and self-maintaining systems) and importantly, phenomenology (importance of subjective experience in understanding cognition). Mark discusses 4E cognition and, interestingly drew a distinction between that enquiry and the extended version from Clark and Chalmers, which he described as representationalism and functionalism “via the back door”.
In my opinion, the biggest shift in psychology between political right and left is ascribing agency to the individual (right) vs collective (left). Or in FEP terms, it means an “internalist-leaning” vs “externalist-leaning” account of cognition. Libertarians worry about the government stealing their agency because they think agency is pointillistic and malleable, people on the left think that we don’t have any individual agency anyway and governance should focus on causes rather than effects.
I got significant pushback, because there is still shedloads of “wiggle room” for how we interpret agency, even between FEP adherents.
Enactivists are generally phenomenologists, which is anathema to “we don’t need biology” physicalism. There is a significant tension between folks who think intelligence is grown vs designed or something in-between.
But the point is that having a position on agency is interpreted politically (it wasn’t intended in this way, and I genuinely didn’t think about it before it was pointed out in the YouTube comments).
Agents don’t actually plan*
A lie told often enough becomes the truth — Vladimir, Lenin
The main argument I was making in the MLST show was an instrumentalist one — instead of individual agents in the real world independently and explicitly calculating all possible future trajectories, the process of planning and decision-making could be understood as a distributed computation which occurs within the broader system. This is so unimaginably complex that in some sense comprehending it completely is beyond our cognitive horizon. This encompasses not just the agents themselves but also their interactions and the mutual information shared among them. Agency is collective process that emerges from the dynamic interplay of various elements within the system. In simple terms, individual agents don’t do as much cognising as we think they do.
To put it another way, the agents are not solely and independently responsible for all the complex calculations involved in planning. They are part of a larger network where information and potential outcomes are processed in a more distributed and interconnected manner. This approach to understanding agency and planning goes against the traditional view of these processes as being wholly centralised within individual agents.
Professor Friston explains this in technical terms at 10:00 (generalised synchronisation of chaos in biological self-organisation) - which he also exquisitely exposited in "Life as we know it" by Friston (2013)
There is no intentionality or goals in general in any real physical process (at least not in the abstract way we humans understand them). Evolution serves as a wonderful example because most people would agree with Daniel Dennett's argument that it's a blind, algorithmic process which operates through natural selection and only appears to be teleological/directed. Guess what, humans are no different. Goals are a model of how we think, not what is.

Consider the phenomenon of carcinization, the evolutionary process that has led unrelated species to converge on a crab-like form. Is this a mere quirk of nature, or does it signify a deeper behavioural or mechanistic pattern?
Carcinization is a form of "morphologically convergent" evolution. It makes it appear as if there is planning in the process, when in fact, there isn’t. For some reason it’s obvious to us that evolution doesn’t plan, yet many cognitive scientists are convinced that we humans do. I see this as being closely related to Kenneth Stanley’s ideas on why greatness cannot be planned - he’s basically saying goals are epistemic road blocks. Perhaps Kenneth’s words are still ringing in my ears - he’s one of the most perceptive AI researchers I have ever encountered. Just like Kenneth Stanley’s Picbreeder, the real source of “entropy” (novel complexity) is humans and physical processes, or processes which supervene on physical processes. Humans going about their daily lives have access to rich, diverse sources of “entropy” and help preserve it. To create any divergent and creative process in AI, you probably need to farm entropy from humans.

AI researchers design with goals
There are several elephants in the room here. If goals are only an anthropocentric instrumental fiction, why do so many AI researchers, think that explicitly modelling them would lead to AGI? Almost all AI researchers "think in goals" whether they are arguing that humans will become extinct, or when designing or constraining what they believe to be proto-"AGI" systems.
Why do so many researchers agree that the reward is enough paper was teleologically misguided, yet think explicit goals are fair game? Rich Sutton was perhaps onto something with his bitter lesson essay - he warned against anthropocentrism in AI system design - ironically though he fell foul of his own advice (the reward part!).
Why assume that adding goal-directed constraints to an emergentist, self-organising principle would yield the same types of intelligent behaviour as in the natural world?
AIs which explicitly plan like AlphaGo, are not doing it the way it actually happens in physical reality. You could argue that it was "planning which explains carcinization". The reality is much more mundane (or complex depending on how you look at it!), but we use the lens of planning to explain the world.

It’s already obvious to me that adding a search process with a predefined goal on top of an LLM won’t create truly new knowledge. New knowledge is paradigmatically new, it’s inventive. Current AIs only search through a relatively tiny predefined space, and there are strict computational limitations on the space and the search process. The miracle of human cognition is that we can apparently overcome exponential complexity both in how we understand the world, and invent new things.
Many representationalist/internalist AI researchers do think that humans and perhaps animals do explicit planning with goals. Many would concede it’s more diffused “in the real world” but would still happily use “internalist” cognitive models for their AI work.
Active inference frames this behaviour in terms of Bayesian statistics. Systems are considered to have generative models—internal representations of how they think the world works—and they update these models based on sensory input in a way that is consistent with Bayesian updating. We will leave the structure learning part out for now, but that makes the job even harder to do in a “plausibly natural” way. But given this instrumental vs realist confusion, does the magic trick still work when explicitly realised?
My main argument for precluding the existence of AGI is that intelligence is at least a very complex physical process. I think it would be possible to achieve AGI as it exists with a very high resolution simulation of a physical process, which in my opinion would be computationally intractable and like Wolfram says when he talks about computational irreducibility, there are no shortcuts!
This is a video of Professor Kristinn R. Thorisson suggesting that he thinks goal-orientedness should be baked into our conception of intelligence.

We could go philosophical on whether goals ontologically "exist". The philosopher Philip Goff argues for an account of panagentialism in his new book “Why? The purpose of the universe” which is to say, perhaps agentialism is knitted into the universe itself, and has locally fractionated degrees of it, or perhaps even arises from it.
From a nativist and psychology perspective, I believe goals exist in us and shape how we think about things (for example Daniel Dennett's intentional stance). But I think they are largely instrumental not realist. Which is to say, they exist only as knowledge and they shape how we think. Explicitly imputing them into AI isn’t a fools errand, but it will produce systems with truncated agency.
But Tim! What about “understanding”. You have gone to great lengths to defend John Searle’s Chinese room argument. Couldn’t it be said that understanding is also a fictionalist and instrumental account, an imagined property of functional dynamics? This is exactly what Francois Chollet said when we interviewed him last.
I must admit, this is a conundrum for me and goes to the core of the “phenomenal resentment” I depicted in the Venn diagram above. The reason Enactivists and statistical mechanics folks are strange bedfellows rests on the philosophy of phenomenology. This is the bright line between the simple physics interpretation of understanding and the ontologically subjective one which Searle advocates for.

In cognitive psychology, there appears to be a widespread consensus that goals play a foundational role in cognition. This perspective is supported by the work of Elizabeth Spelke, who, in her seminal paper on core knowledge, highlights the role of goals as a primitive of cognitive processes. According to Spelke, one of the core knowledge systems humans possess is focused on agents and their goal-directed actions. Goals serve as a crucial element which undergird the way human infants interpret the behavior of other beings as intentional and meaningful.
Spelke and her colleague Katherine D. Kinzler argue that core knowledge systems guide and shape mental lives, and among these systems is one which is attuned to agents and their actions, fundamentally characterised by the concept of goals. They posit that the recognition of goal-directed behavior forms the basis of how we understand agentive behavior.
The emphasis on goal-directed actions signals that even at a very early stage of development, human infants possess an inherent ability to perceive and interpret the actions of others in a manner that assumes an underpinning goal or intent.
The idea that an ability to recognise goals is an evolutionary and developmental precursor to more complex cognitive processes echoes the instrumental role that goals play in implementations of active inference models. It suggests that the way humans and potentially other animals navigate their environments and make decisions is deeply informed by an intrinsic understanding of goal-oriented behavior. Goals seem to be the very substance that fuels the engine of cognition in humans, but - are they just an instrumental fiction or reflect some deeper ontological reality? If you are from a psychology-influenced strand of AI such as expert systems, you would probably believe so. The design vs emerge debate is one of the biggest in AI and is the premise of Rich Sutton’s bitter lesson essay.

Dr. Tim Scarfe - MLST
 | A guest post by
|
"Many representationalist AI researchers do think that agents have internal representation of the world and do explicit planning." -- most people I know who do cognitive modelling (who are more or less aligned with neurosymbolic AI) would not have a problem with the world model / generative model / representation being somewhat external or distributed, as long as it can be *interrogated*. It must be able to be used as a model, to run simulations, otherwise what is the point of having it at all?
Other points of feedback if you are planning to use this as springboard for further: it might be worth having a good, lay, watertight definition or explanation of what entropy is somewhere. Also, the wall of fire para is pretty speculative and vague. Could be a really nice idea if developed a bit?
The Cultural Intelligence of humanity, developed over a 100k span, and in particular its Language component, is the basis for what we call Artificial Intelligence today. Humans stopped evolving biologically and evolution continued first through Cultural Intelligence and now through Technological Intelligence.